下图展示了这些方法如何在机器人基础模型中发挥作用。
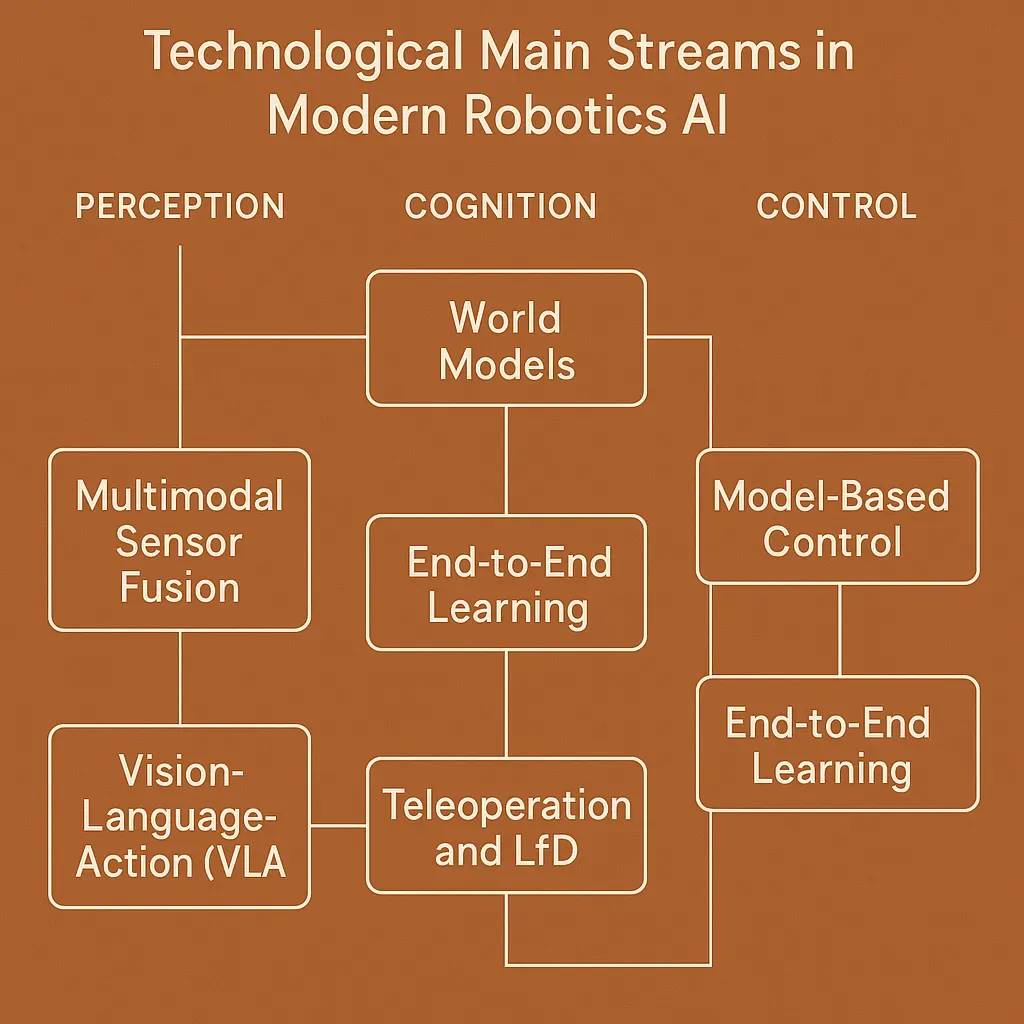
来源:世界模型:推动 AGI 的物理智能核心(World models: the physical intelligence core driving us toward AGI)
最近的一些开源突破,例如 Physical Intelligence 的 π0 和英伟达的 Isaac GR00T N1,标志着该领域的重要进展。然而,大多数机器人基础模型仍然是中心化和闭源的。Covariant、Tesla 等公司仍然保留专有代码和数据集,主要是因为缺乏开放的激励机制。
这种透明度的缺失限制了机器人平台之间的协作和互操作性,凸显了对安全透明的模型共享、社区治理的链上标准以及跨设备互操作性层的需求。这种方法将促进信任、合作,并推动该领域更强大的发展。
1.3 数据层:大脑的“知识”强大的机器人数据集依赖于三个支柱:数量、质量和多样性。
尽管行业在数据积累方面已有所努力,但现有机器人数据集的规模仍远远不足。例如,OpenAI 的 GPT-3 是基于3000亿个标记训练的,而最大的开源机器人数据集 Open X-Embodiment 仅包含超过100万个真实机器人轨迹,涵盖22种机器人类型。这与实现强大的泛化能力所需的数据规模相比,差距巨大。
一些专有方法,例如特斯拉通过数据工厂收集数据,让工作人员穿戴动作捕捉服生成训练数据,确实能够帮助收集更多的真实运动数据。然而,这些方法成本高昂,数据多样性有限,且难以扩展。
为应对这些挑战,机器人领域正在利用以下三种主要数据来源:
-
互联网数据:互联网数据规模庞大且易于扩展,但主要是观察性数据,缺乏传感器与运动信号。通过在互联网数据上预训练大型视觉语言模型(如 GPT-4V 和 Gemini),可以提供有价值的语义和视觉先验。此外,为视频添加运动学标签能够将原始视频转化为可操作的训练数据。
-
合成数据:通过模拟生成的合成数据能够快速进行大规模实验并涵盖多样化场景,但无法完全反映现实世界的复杂性,这一局限被称为“模拟到现实差距”(sim-to-real gap)。研究人员通过领域适配(如数据增强、领域随机化、对抗学习)和模拟到现实迁移来解决这一问题,迭代优化模型并在现实环境中进行测试和微调。
-
真实世界数据:尽管稀缺且昂贵,真实世界数据对于模型的落地和弥合模拟与实际部署之间的差距至关重要。高质量的真实数据通常包括第一视角(egocentric views),记录机器人在任务中“看到”的内容,以及运动数据,记录其精准动作。运动数据通常通过人类示范或远程操作采集,利用虚拟现实(VR)、动作捕捉设备或触觉教学,确保模型从准确的真实例子中学习。