问题出在当前 zkEVM 的工作方式上。它们并非直接对 EVM 进行零知识证明,而是对 EVM 的解释器进行证明,而该解释器本身又被编译为 RISC-V。Vitalik Buterin 直言不讳地指出了这一核心问题:
“……如果 zkVM 的实现方式是将 EVM 的执行编译为最终成为 RISC-V 代码的内容,那为什么不直接将底层的 RISC-V 暴露给智能合约开发者?这样可以完全减免整个外层虚拟机的开销。”
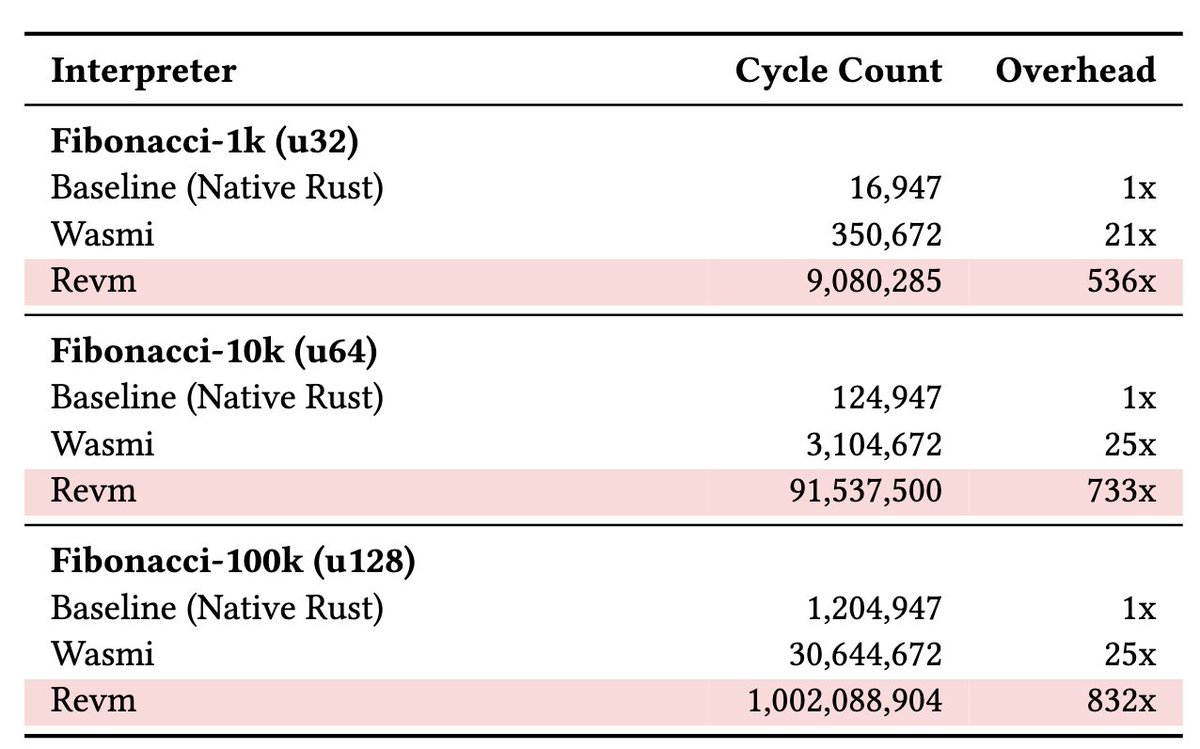
这一额外的解释层带来了巨大的性能损失。估算表明,与证明原生程序相比,这一层可能导致 50 到 800 倍的性能下降。在优化其他瓶颈(如通过切换到 Poseidon 哈希算法)后,这部分“区块执行”仍会占据所有证明时间的 80-90%,使 EVM 成为扩展 L1 的最终且最棘手的障碍。通过移除这一层,Vitalik 预计执行效率可能会提升 100 倍。
技术债务陷阱为了弥补 EVM 在特定密码学操作中的性能不足,以太坊引入了预编译合约——直接硬编码到协议中的专用功能。虽然这一解决方案在当时显得务实,但如今却引发了 Vitalik Buterin 所称的“糟糕”局面:
“预编译对我们来说是灾难性的……它们极大地膨胀了以太坊的可信代码库……并且它们曾导致我们几次几乎发生共识失败的严重问题。”
这种复杂性令人震惊。Vitalik 举例说明,单个预编译合约(如 modexp)的包装代码比整个 RISC-V 解释器还要复杂,而预编译的逻辑实际上更为繁琐。添加新的预编译合约需要通过缓慢且充满政治争议的硬分叉过程,这严重阻碍了需要新密码学原语的应用创新。对此,Vitalik得出了明确的结论:
“我认为我们应该从今天开始停止添加任何新的预编译合约。”
以太坊的架构技术债务EVM 的核心设计反映了过去时代的优先级,但它已不适用于现代计算需求。 EVM 选择了 256 位架构以处理密码学值,但对于智能合约中通常使用的 32 位或 64 位整数来说,这种架构效率极低。这种低效在 ZK 系统中尤为昂贵。正如 Vitalik 所解释的:
“当使用较小的数字时,每个数字实际上不会节省任何资源,而复杂性则会增加两到四倍。”
除此之外,EVM 的堆栈架构比 RISC-V 和现代 CPU 的寄存器架构效率更低。它需要更多指令才能完成相同的操作,同时也使编译器优化更加复杂。
这些问题——包括 ZK 证明的性能瓶颈、预编译的复杂性以及过时的架构选择——共同构成了一个令人信服且紧迫的理由:以太坊必须超越 EVM,迎接更适合未来的技术架构。