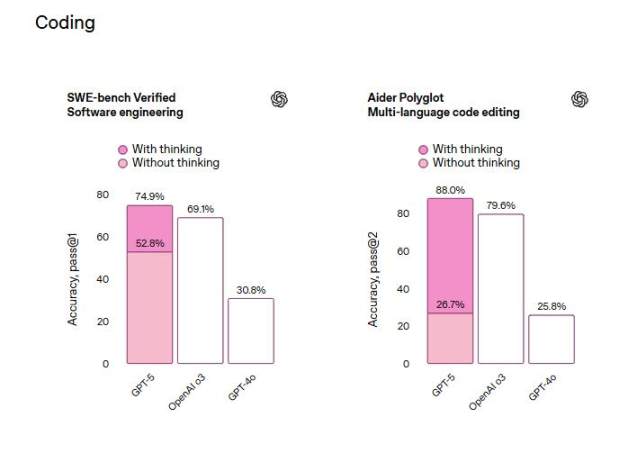
评论指出,这意味着,GPT-5 的表现略胜于 Anthropic 周二推出的 Claude Opus 4.1 和谷歌 DeepMind 的 Gemini 2.5 Pro,后两者在 SWE-bench Verified 测试的得分分别为 74.5% 和 59.6%。
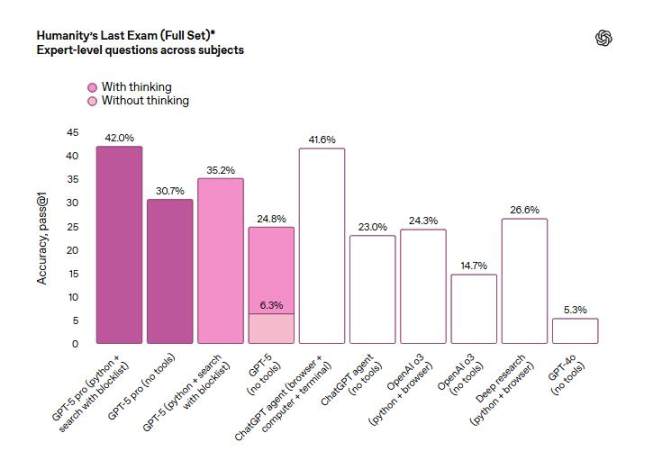
不过,在衡量数学、人文和自然科学领域模型表现的各学科专家级能力 Humanity『s Last Exam 测试中,带有扩展推理功能的 GPT-5 增强版本 GPT-5 pro 在使用工具的情况下得分 42%。这略低于得分 44.4% 的 xAI 模型 Grok 4 Heavy。
Altman 称,GPT-5 尤其擅长按需启动整个软件 App,也就是所谓的「氛围编码」、即用 AI 根据自然语言提示生成功能代码,从而加快开发速度。
作为实例,OpenAI 的研究者演示了,要求 GPT-5 创建一款网页 App,帮助说英语的用户学习法语,且该 App 必须有一个引人入胜的主题,包含抽认卡、测验、经典的贪吃蛇游戏,以及追踪每日学习进度的方法。
研究者将相同的提示词提交到两个 GPT-5 窗口中,几分钟后生成了两个不同的 App。OpenAI 的负责人称,这些 App「存在一些缺陷」,但用户可以根据个人喜好再调整 AI 生成的软件,例如更改背景或添加更多标签页。
在创意写作方面,GPT-5 能够处理结构复杂的写作任务,如无韵律的抑扬格五音步诗或自然流动的自由诗。OpenAI 的 ChatGPT 业务副总 Nick Turley 表示,GPT-5 在创意任务上表现出「更好的品味」,响应更自然。

健康咨询是第三个重要提升领域。
GPT-5 能更积极地标记潜在健康问题,帮助用户解析医疗结果,尽管 OpenAI 强调,ChatGPT 不能替代医疗专业人员。
在名为 HealthBench Hard Hallucinations 的测试中,具备思考能力的 GPT-5 出现幻觉的错误信息率仅为 1.6%。这远低于 GPT-4o 和 o3 模型,后两者的错误信息率分别为 15.8% 和 12.9%。

OpenAI 称,GPT-5 相比此前的模型更可靠和实用,它能更准确地回答现实世界的疑问,出现幻觉的可能性显著降低。
在对代表 ChatGPT 生产流量的匿名提示词启用网络搜索后,GPT-5 响应中包含事实错误的可能性比 GPT-4o 低约 45%;在思考后,GPT-5 响应中包含事实错误的可能性比 o3 低约 80%。下图可见,GPT-5 响应的错误信息率仅为 4.8%,GPT-4o 为 20.6%,o3 为 22%。
